

[C++高性能计算]-CPU加速运算-CUDA程序基础例程
当我们需要进行大规模计算时,我们为了提高计算速度,必然需要GPU加速,例如进行生物信息学单细胞转录组分析时,我们需要对转录组矩阵进行上亿次的计算,如果单用GPU进行计算,速度必然难以满足需求。
对于GPU加速,当下最为广泛用于科学计算的GPU加速方法即NVIDIA的CUDA程序框架,除此之外,在CUDA出现早期,大规模的科学计算的GPU加速也使用OpenGL,但是OpenGL对于图像渲染加速有独特的优势,对于科学计算加速,需要将计算转换为着色器语言,学习曲线较陡,不易于科学计算,因此我们对CUDA科学计算进行研究。
一、CPU和GPU计算的优劣区别
在进行GPU加速计算前,我们首先需要理解CPU和GPU各自的优劣,因为我们只有这样才能更好的选择何时用CPU计算,何时使用GPU计算。
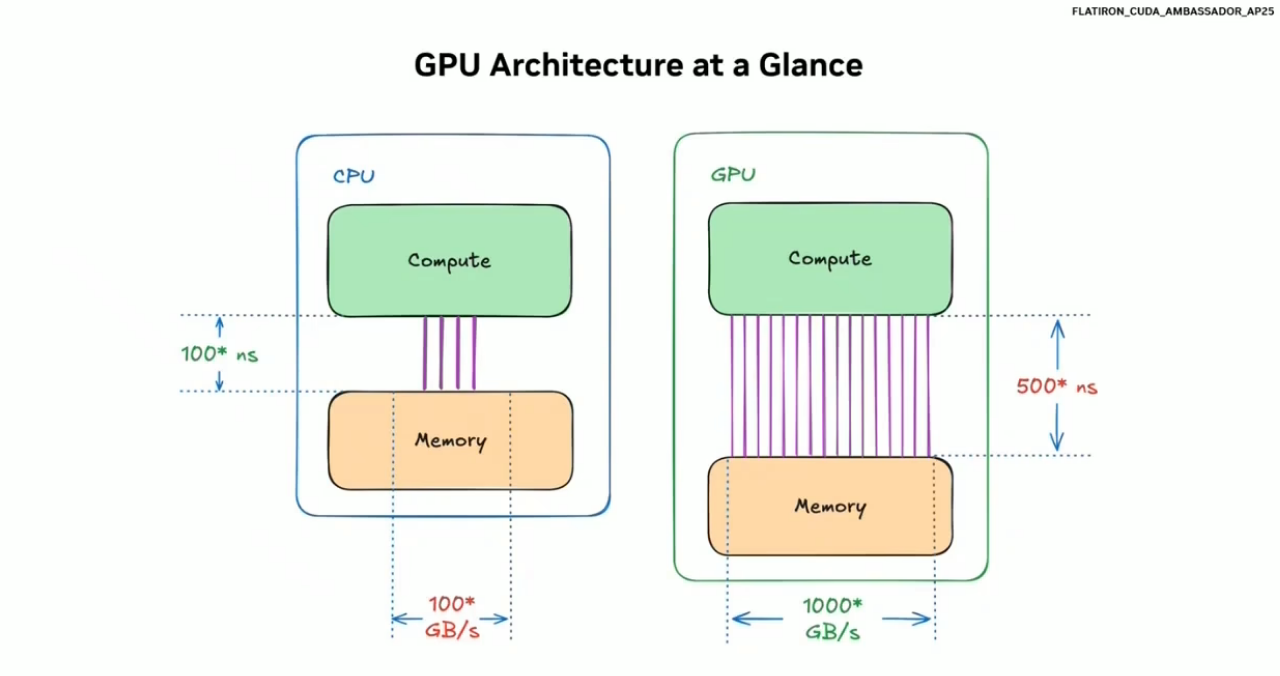
对于CPU计算,你可以理解为CPU是一辆小汽车,CPU进行通讯的数据带宽较窄,仅有100GB/S,但是CPU的计算速度相对较快,对于少量数据,CPU进行计算具有独特优势和性能。
对于GPU计算,你可以理解为GPU是一辆大型客车,GPU进行通讯的数据带宽较广,有1000GB/S,但是GPU的速度相对较缓慢,对于少量数据无法展现出GPU的独特优势,单次计算的时间相对较长,但是对于大量数据,GPU则能根据及其大的带宽展现出相对于CPU惊人的速度。
但是,多大的数据才能展现出GPU的独特优势呢?由下图可以看到,在512个元素计算时,单线程CPU的计算时间远远低于64线程和GPU的计算速度。当数据量增加到65536(六万)个元素计算时,单线程CPU不如64线程CPU的计算速度,但是总体看GPU的优势仍然未展现出。当数据率骤增到268435456(两亿)个元素计算时,GPU的优势明显。

(图片表来自NVIDIA)
二、CUDA基本方法
在开始之前,我们需要引入这些关键c++核心库文件和CUDA核心库文件。
//首先我们需要引入这些头文件
#pragma once
#include <iostream> // 标准输入输出头文件
#include "cuda_runtime.h"//CUDA进行计算的内存,数据传输等等核心API头文件
#include "device_launch_parameters.h"//CUDA核函数启动配置头文件
#include <stdio.h>//标准库文件1.构建核函数
我们需要构建进行运算的核函数,核函数就是我们需要再device(GPU)上运行进行计算的函数,需要用__global__进行声明,如果没有global声明,我们的代码是对CPU可读的,但GPU无法读,所以global声明后,我们的函数可以对全局可见。核函数调用的格式如下:
kernel<<<Dg, Db, Ns, S>>>(param list);其中<<<>>>中是核函数的配置参数,而括号()中的参数是标准的传递给核函数的参数。
Dg(Grid 维度): 类型:int 或 dim3(x, y, z)。 用于定义一个 grid 中的 block 是如何组织的。int 类型表示一维组织结构,dim3 类型表示多维组织结构。
Db(Block 维度): 类型:int 或 dim3(x, y, z)。 用于定义一个 block 中的 thread 是如何组织的。int 类型表示一维组织结构,dim3 类型表示多维组织结构。
Ns(动态共享内存大小): 类型:size_t,可缺省,默认为 0。 用于设置每个 block 除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为字节。0 表示不需要动态分配。
S(流): 类型:cudaStream_t,可缺省,默认为 0。 表示该核函数位于哪个流中执行。
目前无需深入理解这些,我们后续对核函数线程配置时再深入讨论。这是我们构建的一个普通的加法计算核函数。结果参数我们设定为指针,这样我们便于后续将GPU计算结果复制到CPU中进行下一步处理,我们后续再main函数中进行调用。
__global__ void addKernel(int a,int b,int* c) {
*c = a + b;
}2.CUDA中内存的操作
我们在计算时,计算得到的数据是存储在device(GPU显存)上面,因此我们不能用C库中以往的mallco函数申请内存空间,mallco函数申请的是CPU内存上的空间。同样我们在GPU上申请内存空间后存储数据结果,还需要复制到CPU内存上,进行进一步处理(当然也可以将CPU上的内存复制到GPU)。我们需要特定的两个函数cudaMallco和cudaMemcpy,分别用来申请内存空间和复制内存。
cudaError_t cudaMalloc(void** devPtr, size_t size)cudaMallco函数的参数第一个是申请的设备内存空间的二级指针,用来存放在显存中申请到的内存空间的地址。第二个参数是申请的内存空间的大小,一般用sizeof()或取需要存放的数据类型大小即可。
cudaError_t cudaMemcpy(void *dist, const void* src,size_t count,CudaMemcpyKind kind)有四个,第一个是dist 目标地址的指针,第二个是源地址的指针,即用来将源地址处的内存复制到目标地址处的内存。count参数是复制的内存空间大小,cudaMemcpyKind 类型的kind参数是进行复制的内存空间的类型,例如从device(GPU)复制到host(CPU),反之亦然。
参数kind的值有如下:
——1.cudaMemcpyHostToHost
——2.cudaMemcpyHostToDevice
——3.cudaMemcpyDeviceToHost
——4.cudaMemcpyDeviceToDevice
他们的返回值均为cudaError_t类型的数据,其本质是一个int类型的cuda状态码,我们可以利用返回值进行检验操作是否成功。
cudaError_t cudaStu;
cudaStu = cudaMalloc((void**)&dev_c,sizeof(int));
if (cudaStu != cudaSuccess) {
fprintf(stderr, "CUDA dev_c Malloc error code %d", cudaStu);
goto ERROR;
}最后我们运算结束后,还需要将申请的内存空间释放,明显我们不能用C库以往的free函数释放内存,因为内存空间在device(GPU)中,我们需要特定的函数cudaFree进行内存释放操作。
3.完整代码流程
您也可以前去CSDN博客查看完整文章https://blog.csdn.net/qq_39129185/article/details/156995968?spm=1011.2415.3001.5331

